注意:以下文档只适用于TOP接口,请谨慎使用!


注意:以下文档只适用于TOP接口,请谨慎使用!
微软的定义:
计算某个值在SQL Server 2012中的一组值内的累积分布。CUME_DIST计算某指定值在一组值中的相对位置。对于行r,假定采用升序,r的CUME_DIST是值低于或等于r的值的行数除以在分区或查询结果集中求出的行数。
函数解析:
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000),
- ('andy02','bd',12000),
- ('andy03','bd',12000),
- ('andy04','bd',10000),
- ('andy05','bd',8000),
- --ca
- ('andy06','ca',20000),
- ('andy07','ca',18000),
- ('andy08','ca',18000),
- ('andy09','ca',15000),
- ('andy10','ca',12000),
- ('andy11','ca',12000),
- ('andy12','ca',10000),
- ('andy13','ca',8000),
- ('andy14','ca',8000),
- ('andy15','ca',8000)
- SELECT
- dept,name ,salary,
- CUME_DIST() OVER(PARTITION BY dept ORDER BY salary) AS cume_dist_
- FROM @analytic
- ORDER BY dept,salary DESC
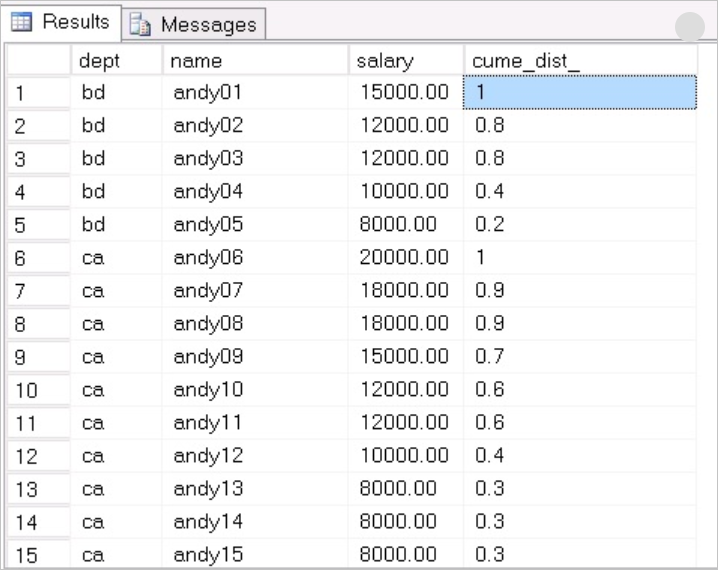
返回结果如下:
示例解析:
按照dept分组,根据salary逻辑排序,针对每一个分组里的每一个值,计算在该分组下等于或者小于自己的salary的分布的百分比。举个例子,bd部门的andy02,salary为12000,那么等于或者小于这个12000的有4条,总共5条记录,因此那么CUME_DIST()=4/5=0.8。 同理,其它也是这样计算。
微软的定义:
返回SQL Server 2012中有序值集中的最后一个值。
函数解析:
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money ,
- hiredate date
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000,'2002-01-09'),
- ('andy02','bd',12000,'2003-01-09'),
- ('andy03','bd',12000,'2003-02-09'),
- ('andy04','bd',10000,'2005-05-09'),
- ('andy05','bd',8000,'2003-06-09'),
- --ca
- ('andy06','ca',20000,'2003-01-09'),
- ('andy07','ca',18000,'2005-02-09'),
- ('andy08','ca',18000,'2005-03-09'),
- ('andy09','ca',15000,'2004-01-09'),
- ('andy10','ca',12000,'2003-06-09'),
- ('andy11','ca',12000,'2002-09-09'),
- ('andy12','ca',10000,'2003-07-09'),
- ('andy13','ca',8000,'2003-08-09'),
- ('andy14','ca',8000,'2003-11-09'),
- ('andy15','ca',8000,'2003-01-09')
- SELECT
- dept,name ,salary,hiredate,
- LAST_VALUE(hiredate) OVER(PARTITION BY dept ORDER BY salary) AS last_value_
- FROM @analytic
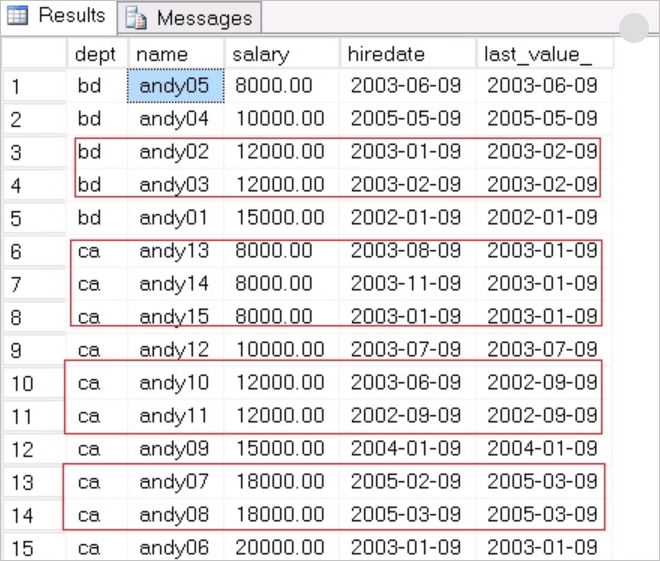
返回结果如下:
示例解析:
按照OVER子句中ORDER BY根据salary排序,取salary最后行的hiredate值作为最后的LAST VALUE,重点在于当salary有相同的值时,需要取根据salary排序后的最后一条记录作为其他的LAST VALUE。
微软的定义:
返回SQL Server 2012中有序值集中的第一个值。
函数解析:
从微软的定义来看,FIRST_VALUE似乎跟LAST_VALUE是相反的含义,但实际并非如此。
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money ,
- hiredate date
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000,'2002-01-09'),
- ('andy02','bd',12000,'2003-01-09'),
- ('andy03','bd',12000,'2003-02-09'),
- ('andy04','bd',10000,'2005-05-09'),
- ('andy05','bd',8000,'2003-06-09'),
- --ca
- ('andy06','ca',20000,'2003-01-09'),
- ('andy07','ca',18000,'2005-02-09'),
- ('andy08','ca',18000,'2005-03-09'),
- ('andy09','ca',15000,'2004-01-09'),
- ('andy10','ca',12000,'2003-06-09'),
- ('andy11','ca',12000,'2002-09-09'),
- ('andy12','ca',10000,'2003-07-09'),
- ('andy13','ca',8000,'2003-08-09'),
- ('andy14','ca',8000,'2003-11-09'),
- ('andy15','ca',8000,'2003-01-09')
- SELECT
- dept,name ,salary,hiredate,
- FIRST_VALUE(name) OVER(PARTITION BY dept ORDER BY salary) AS first_value_
- FROM @analytic
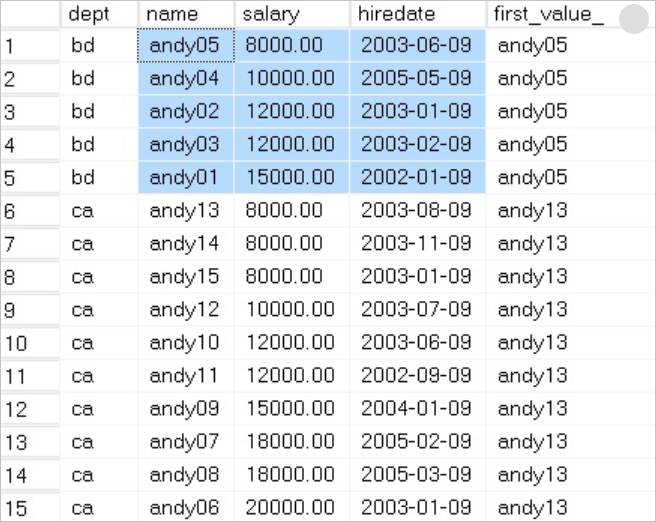
返回结果如下:
示例分析:
显然,这个与LAST_VALUE并不是相反的含义。OVER子句根据ORDER BY来排序,按dept分组来确定这个分组的第一个值,而不是根据salary的值来确定的,所以与LAST_VALUE是不一样的。将FIRST_VALUE(name)修改为FIRST_VALUE(hiredate)后,对比看得更清楚,这个很有蒙蔽性。
微软的定义:
访问相同结果集的后续行中的数据,而不使用SQL Server 2012中的自联接。LEAD以当前行之后的给定物理偏移量来提供对行的访问。在SELECT语句中使用此分析函数可将当前行中的值与后续行中的值进行比较。
函数解析:
执行如下代码,构造一组数据。
- DECLARE
- @analytic TABLE(
- name varchar(35) ,
- dept varchar(35),
- salary money ,
- hiredate date
- )
- INSERT INTO @analytic
- VALUES
- --bd
- ('andy01','bd',15000,'2002-01-09'),
- ('andy02','bd',12000,'2003-01-09'),
- ('andy03','bd',12000,'2003-02-09'),
- ('andy04','bd',10000,'2005-05-09'),
- ('andy05','bd',8000,'2003-06-09'),
- --ca
- ('andy06','ca',20000,'2003-01-09'),
- ('andy07','ca',18000,'2005-02-09'),
- ('andy08','ca',18000,'2005-03-09'),
- ('andy09','ca',15000,'2004-01-09'),
- ('andy10','ca',12000,'2003-06-09'),
- ('andy11','ca',12000,'2002-09-09'),
- ('andy12','ca',10000,'2003-07-09'),
- ('andy13','ca',8000,'2003-08-09'),
- ('andy14','ca',8000,'2003-11-09'),
- ('andy15','ca',8000,'2003-01-09')
- SELECT
- dept,name,hiredate,salary,
- LEAD(salary,1,0) OVER(PARTITION BY dept ORDER BY salary) AS lead_,
- (LEAD(salary,1,0) OVER(PARTITION BY dept ORDER BY salary)-salary) AS diff_salary
- FROM @analytic
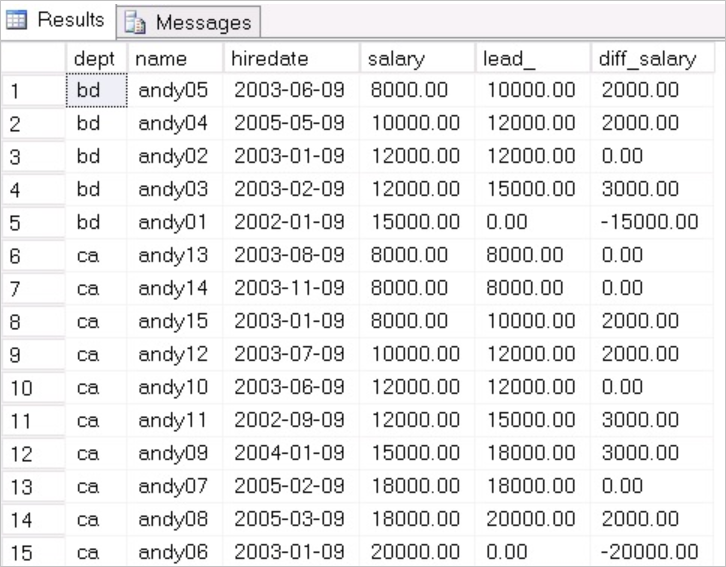
返回结果如下:
示例分析:
按照dept分区,根据salary排序,比较当前记录和后一条记录(偏移量为1)的salary值的差值,这个非常实用。

